OPS 는 On-base Plus Slugging 의 약자로 야구에서 타자를 평가하는 스탯 중 하나로 출루율 (OBP) + 장타율 (SLG) 로 계산한다.
MLB 에서는 꽤 오래 전부터 공식 기록으로 인정받고 있지만 KBO 리그에서는 공식적으로 인정하는 기록이 아니였기 때문에 KBO 홈페이지 기록실에는 2002년도 부터 OBP SLG OPS 기록이 업로드 되어있다.
따라서 2002~2023 년도 기록을 모두 크롤링 하여 데이터를 확보 한 뒤 모델링을 하도록 해본다.
kbo 기록실이 너무 난잡하여...........
다른 참고 사이트인 https://statiz.sporki.com/ 의 기록실을 활용하여
2002년 부터 2023년동안 기록되어 있는 선수들의 기록을 크롤링 하여 모두 1003 명 분의 기록을 크롤링 했다. (표본이 부족할 경우, 전체 기록을 크롤링 하면 될 거 같다. KBO 기록실에는 2002년 부터 OBP SLG OPS 기록이 있지만 스포키에는 84년도 부터 활약한 선수들의 OBP SLG OPS 기록까지 확인 할 수 있었따.)
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 초기 DataFrame 설정
columns = ["Rank", "Name", "ExtraColumn", "ExtraColumn2", "G", "PA", "ePA", "AB", "R", "H", "2B", "3B", "HR", "TB", "RBI", "SB", "CS", "BB", "HP", "IB", "SO", "GDP", "SH", "SF", "AVG", "OBP", "SLG", "OPS", "R/ePA", "wRC+", "WAR"]
data = []
# 년도별 URL 순회
for year in range(2002, 2024):
url = f"https://statiz.sporki.com/stats/?m=main&m2=batting&m3=default&so=WAR&ob=DESC&year={year}&sy=&ey=&te=&po=<=10100®=R&pe=&ds=&de=&we=&hr=&ha=&ct=&st=&vp=&bo=&pt=&pp=&ii=&vc=&um=&oo=&rr=&sc=&bc=&ba=&li=&as=&ae=&pl=&gc=&lr=&pr=50&ph=&hs=&us=&na=&ls=&sf1=&sk1=&sv1=&sf2=&sk2=&sv2="
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 데이터가 있는 테이블을 찾아서 각 행 순회
rows = soup.find('table').find('tbody').find_all('tr')
for row in rows:
cols = row.find_all('td')
if len(cols) > 1: # 헤더나 공백 행이 아닌 경우
col_data = []
for col in cols:
col_data.append(col.get_text().strip())
data.append(col_data)
# DataFrame 생성
df = pd.DataFrame(data, columns=columns)
# CSV 파일로 저장
df.to_csv('kbo_player_stats_2002_to_2023.csv', index=False)이렇게 하긴 했는데 생성 된 CSV 파일을 확인 해보니... 문제가 조금 있다.

3번 선수처럼 나와야하는데
1,2번 선수처럼 게임수가 ExtraColumn2 에 입력되었다..
극복해야하는데 어떡해야할 지 모르겠다
하지만 답을 또 찾아내야지
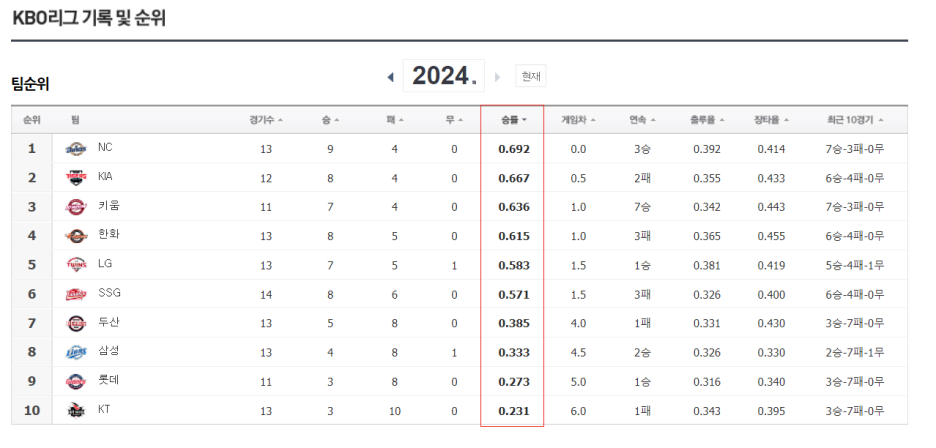

개인적으로 응원하는 NC가 단독 1위에 올라섰다.......행벅.ㅋㅋ.ㅋ.ㅋ.ㅋ.ㅋ.ㅋ.ㅋㅎㅋㅎㅋㅎㅋㅋㅎㅋㅎ
-----------------
같이 팀으로 프로젝트 하고있는 친구가 코드에 한글 인코딩이 안되어서 깨져 나오는거 같다는 의견을 주어 코드를 수정 해봤다!
우리가 흔히 알고있는 한글 인코딩 코드 "utf-8" 을 활용 했으나 똑같이 깨져 나왔다.
한글 인코딩에 대해 조금 더 알아보니
"utf-8-sig" 인코딩을 찾아 인코딩을 시켰더니 잘 나왔다!
|
Rank
|
Name
|
ExtraColumn
|
ExtraColumn2
|
G
|
PA
|
ePA
|
AB
|
R
|
|
1
|
이승엽
|
02 1B
|
8.93
|
133
|
617
|
612
|
511
|
123
|
|
2
|
심정수
|
02 RF
|
7.58
|
133
|
577
|
567
|
502
|
101
|
|
3
|
김동주
|
02 3B
|
6.46
|
120
|
487
|
485
|
415
|
63
|
|
4
|
페르난데스
|
02 3B
|
6.08
|
132
|
556
|
554
|
499
|
81
|
- 수정 코드
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 초기 DataFrame 설정
columns = ["Rank", "Name", "ExtraColumn", "ExtraColumn2", "G", "PA", "ePA", "AB", "R", "H", "2B", "3B", "HR", "TB", "RBI", "SB", "CS", "BB", "HP", "IB", "SO", "GDP", "SH", "SF", "AVG", "OBP", "SLG", "OPS", "R/ePA", "wRC+", "WAR"]
data = []
# 년도별 URL 순회
for year in range(2002, 2024):
url = f"https://statiz.sporki.com/stats/?m=main&m2=batting&m3=default&so=WAR&ob=DESC&year={year}&sy=&ey=&te=&po=<=10100®=R&pe=&ds=&de=&we=&hr=&ha=&ct=&st=&vp=&bo=&pt=&pp=&ii=&vc=&um=&oo=&rr=&sc=&bc=&ba=&li=&as=&ae=&pl=&gc=&lr=&pr=50&ph=&hs=&us=&na=&ls=&sf1=&sk1=&sv1=&sf2=&sk2=&sv2="
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 데이터가 있는 테이블을 찾아서 각 행 순회
rows = soup.find('table').find('tbody').find_all('tr')
for row in rows:
cols = row.find_all('td')
if len(cols) > 1: # 헤더나 공백 행이 아닌 경우
col_data = []
for col in cols:
col_data.append(col.get_text().strip())
data.append(col_data)
# DataFrame 생성
df = pd.DataFrame(data, columns=columns)
# CSV 파일로 저장
df.to_csv('kbo_player_stats_2002_to_2023.csv', index=False, encoding='utf-8-sig')"utf-8-sig" 인코딩은"utf-8"과 유사하지만, 파일 시작 부분에 바이트 순서 표시(BOM)를 추가한다.
이는 특히 Windows에서 UTF-8 BOM 없이는 한국어 문자가 포함된 파일을 올바른 인코딩으로 인식하지 못하는 일부 응용 프로그램과의 호환성을 위해 유용할 수 있다고 한다~!!!
'Project' 카테고리의 다른 글
| [2024 KBO 타자 별 OPS 예측 모델 개발] 예측 해야 할 타자 리스트 작성 2 (0) | 2024.04.08 |
|---|---|
| [2024 KBO 타자 별 OPS 예측 모델 개발] 예측 해야 할 타자 리스트 작성 (0) | 2024.04.08 |
| [2024 KBO 타자 별 OPS 예측 모델 개발] 프로젝트 기획안 (0) | 2024.04.08 |